Wie man einen Finanz-Agenten baut
Eine Schritt-für-Schritt-Anleitung zum Aufbau eines KI-gestützten Finanzagenten — von Subagenten und Tool-Routing bis hin zu Scratchpads und Evaluierungen.

Wie man einen Finanz-Agenten baut
Es ist 16:01 Uhr in New York und NVIDIA hat gerade nach Börsenschluss seine Quartalszahlen veröffentlicht.
Ich öffne einen Haufen Tabs, um die Ergebnisse mit den Analystenschätzungen zu vergleichen, lese den 10-K-Bericht nach der Zukunftsprognose des Managements, prüfe aktuelle Form-4-Meldungen auf Insideraktivitäten vor der Veröffentlichung und scanne Finanznachrichtenseiten nach Analystenreaktionen und der Marktstimmung.
Es gibt sicher elegantere Wege, das alles zu erledigen, aber so mache ich es. An einem guten Tag sind es etwa 30 Minuten Arbeit.
Vor zwei Monaten habe ich einen Agenten namens Dexter als Open Source veröffentlicht, um das schneller zu erledigen. Heute schafft Dexter all das in rund 30 Sekunden — und ist besser darin als ich.
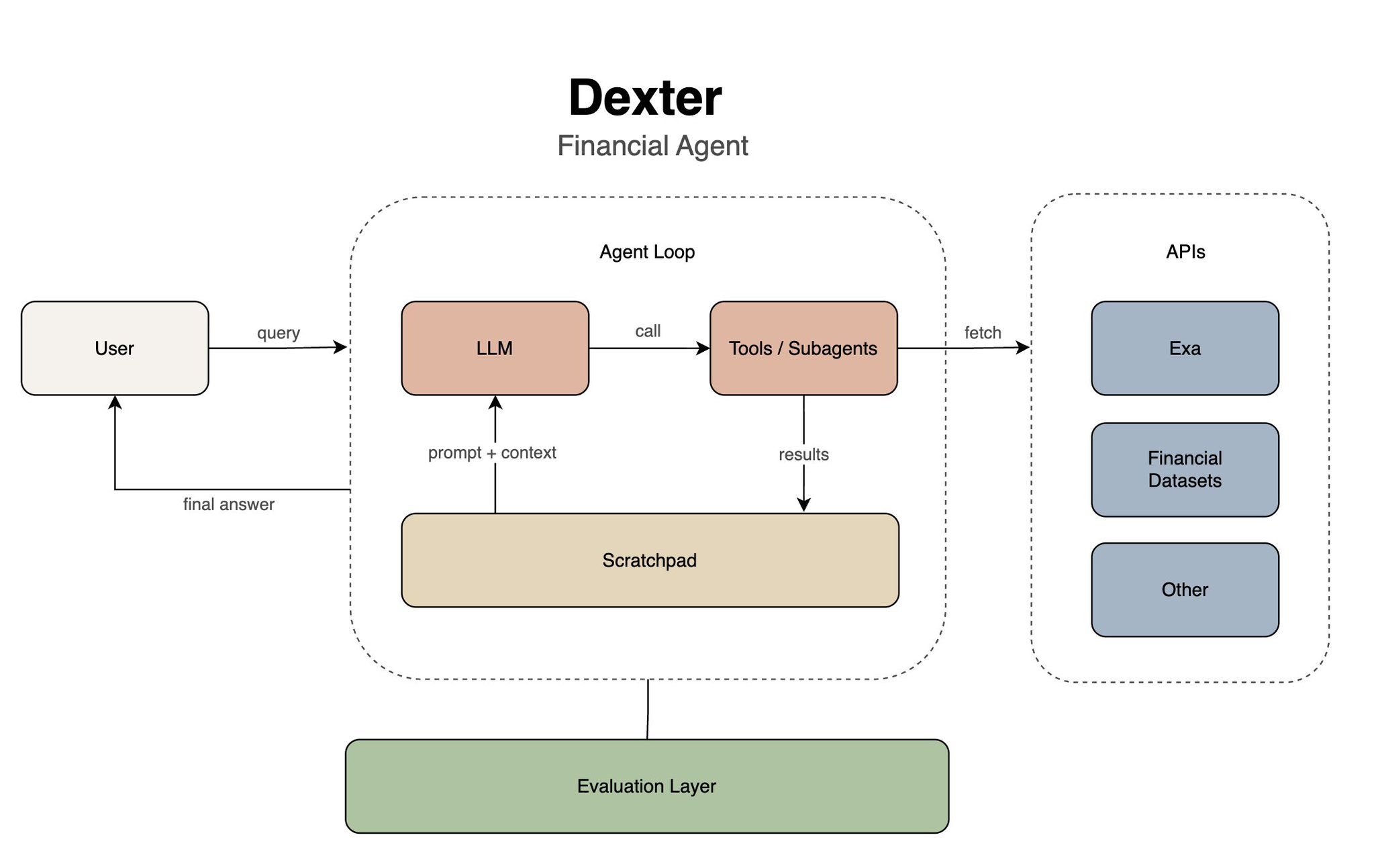
Einfach ist schön. Dexters System besteht aus nur fünf Bausteinen: (1) ein LLM, das denkt und Tools auswählt, (2) Tools, die die eigentliche Arbeit erledigen, (3) externe APIs für Live-Daten, (4) ein Scratchpad, das den Zustand hält, und (5) eine Evaluierungsschicht, um alles offline zu testen.
1. Die Anfrage kommt rein
Das gebe ich in Dexter ein:
„NVIDIA hat gerade die Geschäftszahlen für FY 2025 veröffentlicht. Vergleiche die gemeldeten Ergebnisse mit den Analystenschätzungen der letzten Tage. Zeige Insiderhandelsaktivitäten für das Quartal vor der Veröffentlichung. Hole die Zukunftsprognose des Managements aus dem aktuellsten 10-K (Abschnitt 7, MD&A). Was sagen die Analysten zu den Ergebnissen und wie hat der Markt reagiert?"
Unsere NVIDIA-Anfrage kommt als User-Prompt an. Dexter erhält außerdem einen System-Prompt, der Beschreibungen aller verfügbaren Tools und Richtlinien zu deren Nutzung enthält.
Im System-Prompt sieht Dexter nur:
- Drei Subagenten: Finanzsuche, Finanzkennzahlen und einen SEC-Filings-Leser. Jeder enthält ein eigenes inneres LLM, das an spezialisierte Sub-Tools weiterleitet. Mehr dazu weiter unten.
- Zwei direkte Tools: Web-Browsing und Datei-Browsing.
Beachte, wie klein Dexters „Entscheidungsraum" ist. Er sieht nur 5 Tools. Das ist eine bewusste Designentscheidung, die ich nach einigen Wochen Versuch und Irrtum getroffen habe.
Die erste Version von Dexter legte jeden Endpunkt direkt offen — insgesamt etwa 22. Das LLM konnte „Gewinn- und Verlustrechnungen abrufen", „Insiderhandel abrufen", „Analystenschätzungen abrufen" und ein Dutzend weitere sehen. Manchmal funktionierte es ziemlich gut.
Bis es das nicht mehr tat.
Das Modell rief den richtigen Endpunkt für einen Ticker auf, vergaß aber, ihn für einen anderen erneut aufzurufen. Es holte Finanzkennzahlen, wenn es Gewinn- und Verlustrechnungen brauchte. Es übergab das falsche Datumsformat, weil es mit zu vielen Parameter-Schemas gleichzeitig jonglierte. Bei komplexen Anfragen, die mehrere Rechercheschritte erforderten, wurden die Probleme noch schlimmer.
Warum passierte das? Dexters Entscheidungsraum war zu groß.
Zurück zu unserer NVIDIA-Anfrage: Wenn Dexter unsere Anfrage liest, erkennt sein LLM vier separate Aufgaben: Ergebnisse vs. Schätzungen, Insiderhandel, 10-K-Zukunftsprognose und Marktreaktion. Anstatt das gesamte Abrufen und Berechnen selbst zu erledigen, übergibt Dexter diese Arbeit an seine Subagenten.
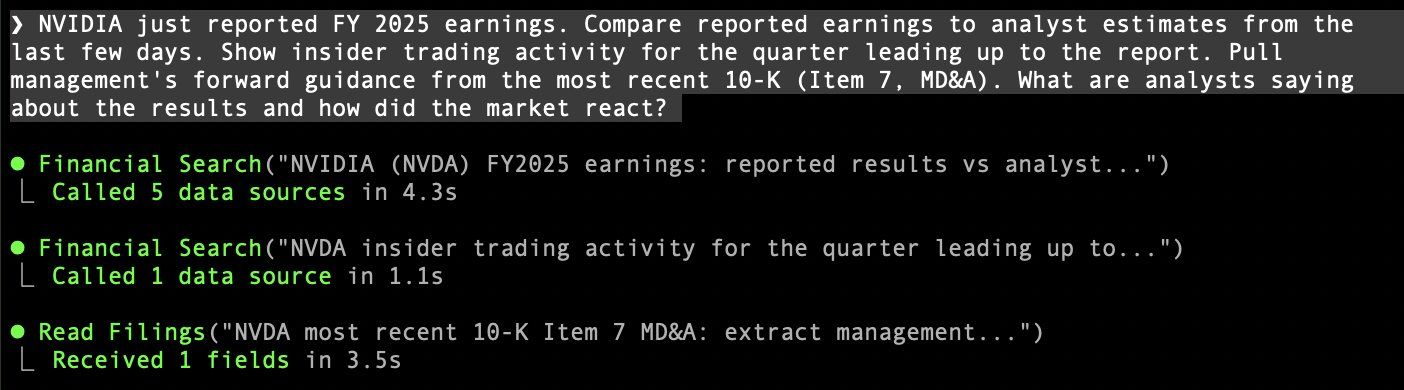
2. Subagenten
Ein Subagent ist ein „Meta-Tool", das sein eigenes LLM und eine eigene agentische Schleife besitzt. Wenn das äußere LLM den Finanzsuche-Subagenten mit „NVIDIA-Ergebnisse vs. Analystenschätzungen und Insideraktivitäten im letzten Quartal" aufruft, übergibt es die Frage an einen kleineren, spezialisierten Agenten. Dieses innere LLM sieht unsere Finanz-Endpunkte — Gewinn- und Verlustrechnungen, Analystenschätzungen, Insiderhandel usw. — und wählt die richtigen aus. Anders als Dexters Haupt-LLM ist dieser Subagent fokussiert. Er hat eine einzige Aufgabe: auf Finanzdaten zugreifen.
Für unsere NVIDIA-Ergebnisanfrage wählt der Finanzsuche-Subagent Analystenschätzungen für NVDA und Insiderhandel für NVDA aus und setzt Datumsfilter für die letzten Tage. Für Geschwindigkeit führt er diese API-Aufrufe parallel aus.
Der Filings-Reader-Subagent funktioniert anders. Statt Tools parallel auszuführen, verkettet er zwei LLM-Aufrufe nacheinander. Der erste identifiziert, welches Filing geholt werden soll (Ticker, Filing-Typ, Datumsbereich). Der zweite extrahiert die Abschnitte, die wir brauchen. Anderer Subagent, andere Architektur, gleiches Muster: spezialisierter Agent, fokussierte Aufgabe.
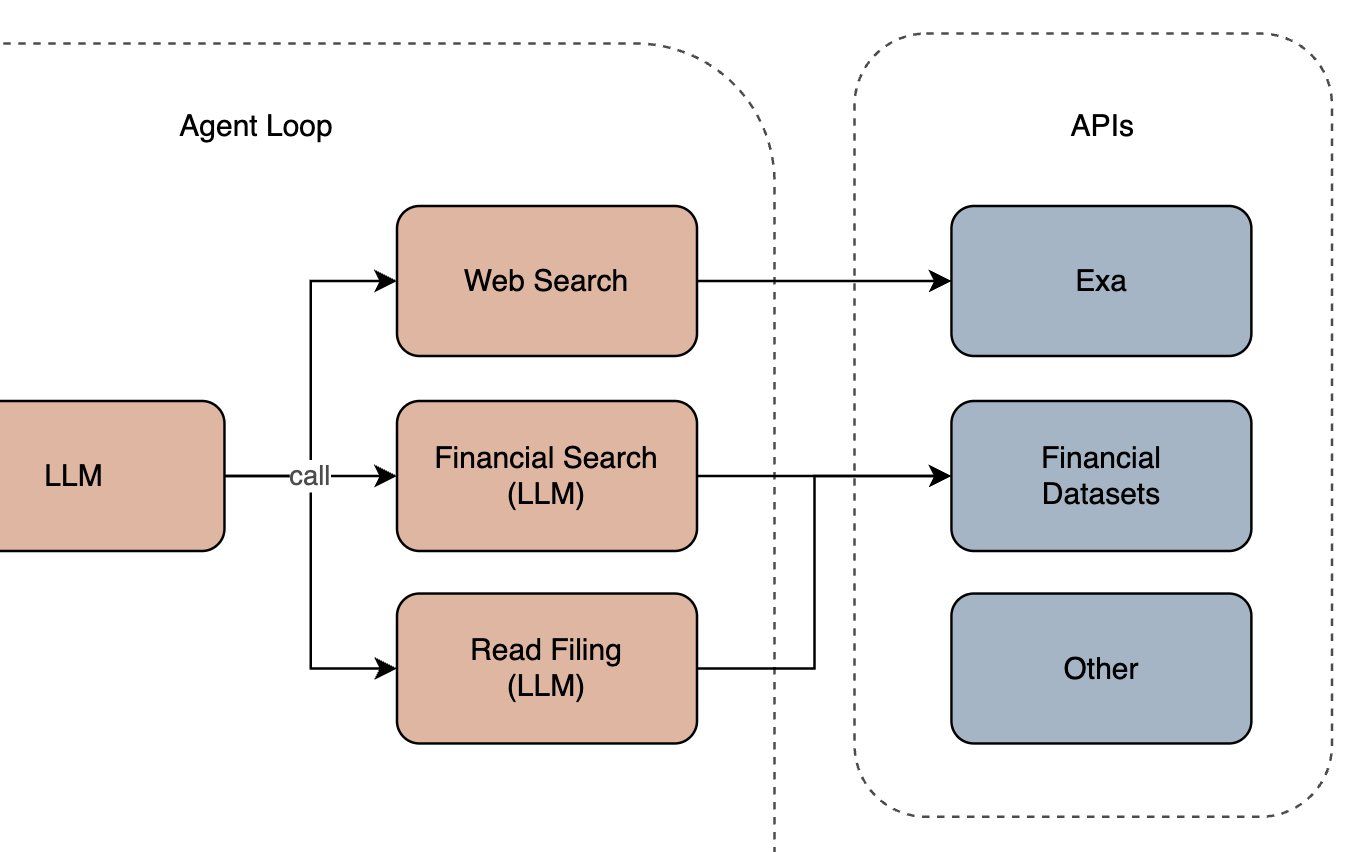
Zentrale Erkenntnis: Subagenten ermöglichen es uns, spezifische Arbeitstypen zu kapseln — wie das Abrufen von Finanzdaten oder das Lesen von SEC-Filings. Subagenten können so angepasst werden, dass sie Experten für die Aufgabe(n) sind, für die sie bestimmt sind. Manche haben agentische Schleifen, andere sind einfacher und rufen LLMs sequenziell auf. Das Schöne daran ist, dass wir so viele bauen können, wie wir wollen. Das äußere LLM routet Aufgaben einfach an die Subagenten — und los geht's.
3. Datenabruf
Die wichtigste Designentscheidung in dieser Schicht: Strukturierte Daten gehen direkt ans LLM — ohne Zusammenfassungsschritt dazwischen. Es gibt keine Middleware, die die Antwort bereinigt oder Schlüsselfelder extrahiert. Das Modell sieht die rohe API-Ausgabe und erledigt die Arbeit selbst.
Das ist wichtig, weil es das System einfach und das Modell ehrlich hält. Analystenschätzungen kommen als Arrays mit Feldern wie geschätztem EPS, tatsächlichem EPS und Berichtszeitraum an. Insiderhandel kommt mit Transaktionstyp, Anzahl der Aktien, Preis pro Aktie und Meldedatum zurück. Wenn das Modell später schreibt „Insiderverkäufe beliefen sich auf 50.000 Aktien zu einem Durchschnittspreis von 142 $", liest es aus Live-Daten — nicht aus dem Gedächtnis.
Für Finanzdaten nutzt Dexter die Financial Datasets API (Hinweis: Ich bin der Gründer von FD). Für die Websuche kaskadiert er durch mehrere Anbieter (Exa, Perplexity, Tavily) und fällt auf einen lokalen Browser zurück, wenn keiner konfiguriert ist. Zum Lesen einer bestimmten Webseite gibt es ein schlankes HTTP-Fetch-Tool, das HTML in sauberes Markdown umwandelt — mit einem vollständigen Playwright-basierten Browser als Fallback für JavaScript-lastige Seiten.
Um Kosten zu sparen, haben wir Caching hinzugefügt. Die Logik ist einfach: Cache, was unveränderlich ist, überspringe, was es nicht ist. SEC-Filings sind rechtlich unveränderlich — kein Grund, sie zweimal abzurufen. Die Gewinn- und Verlustrechnung des letzten Quartals ist ebenfalls unveränderlich. Der aktuelle Kurs-Snapshot ist es nicht. Der Cache liegt in .dexter/cache/ als menschenlesbare JSON-Dateien, was das Debugging schmerzfrei macht.
4. Das Scratchpad
Während Dexter an unserer Aufgabe arbeitet, ruft er Subagenten und Tools auf und sammelt Kontext. All dieser Kontext landet an einem Ort: dem Scratchpad.
Das Scratchpad ist eine Append-Only-JSON-Datei auf der Festplatte. Es ist die einzige Wahrheitsquelle für alles, was Dexter bei der Bearbeitung unserer Anfrage gelernt hat.
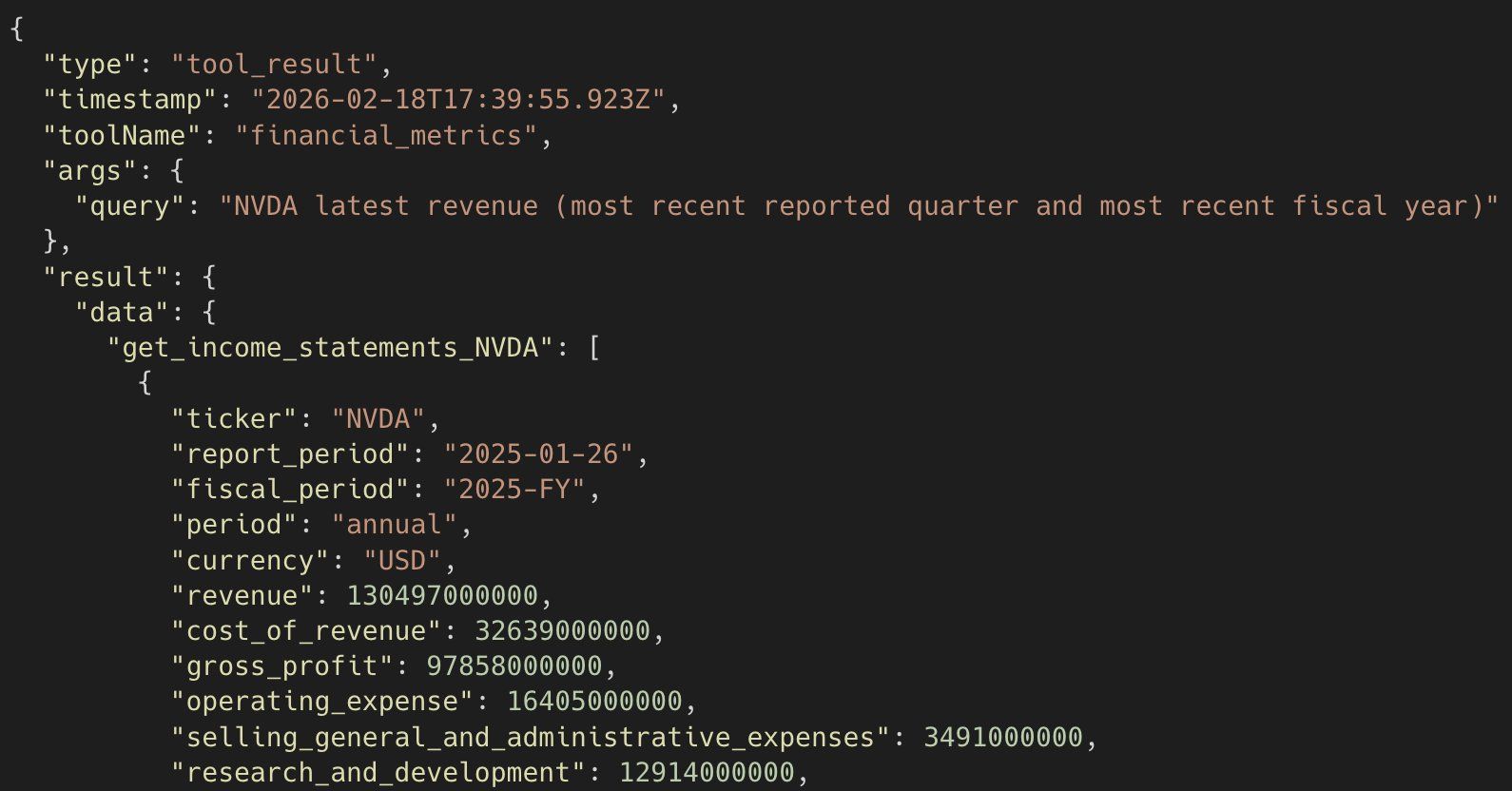
Warum eine Datei und nicht einfach eine Variable im Speicher? Zwei Gründe:
Debugging. Frühe Versionen speicherten Tool-Ergebnisse nur im Speicher. Dexter gab eine seltsame Antwort, ich wollte nachschauen, was er tatsächlich gesehen hatte — und die Daten waren weg. Mit JSONL auf der Festplatte wird jedes Tool-Ergebnis für immer persistiert. Ich kann die Datei nach einem Lauf öffnen, Zeile für Zeile lesen und genau sehen, was passiert ist.
Resilienz. Dexter macht Netzwerkaufrufe, die fehlschlagen können, und ein CLI-Prozess kann mitten im Lauf abstürzen oder beendet werden. Wenn Tool-Ergebnisse nur im Speicher leben, bedeutet ein Absturz: von vorne anfangen. Mit dem Scratchpad auf der Festplatte überlebt die Arbeit den Prozess. Außerdem kann ich unvollständige Läufe inspizieren: Wenn Dexter bei Iteration 6 ein Timeout hatte, kann ich trotzdem sehen, was er bis Iteration 5 gesammelt hat.
Nach der Bearbeitung unserer NVIDIA-Anfrage enthält das Scratchpad nun fünf Ergebnisse: aktuelle Finanzergebnisse, Analystenschätzungen, Insiderhandel, Abschnitt 7 des 10-K und Web-Suchergebnisse. Etwa 15.000 Token. Weit entfernt vom Kontextlimit.
Aber stell dir eine größere Anfrage vor: „Analysiere Risikofaktoren über NVIDIAs letzte drei 10-Ks und vergleiche, wie sie sich verändert haben." Drei vollständige Risikofaktor-Abschnitte könnten allein über 50.000 Token Filing-Text übersteigen. Hier stieß ich auf meine erste echte Skalierungsgrenze. Ohne Leitplanken stopfte Dexter seine gesamte Historie in den Prompt, sprengte das Kontextfenster und brach mit einem Fehler ab.
Die Lösung ist Context Compaction: Nach jeder Runde von Subagent- und Tool-Aufrufen schätzt Dexter die Gesamtanzahl der Token. Überschreitet sie einen Schwellenwert (z.B. 100.000), werden die ältesten Tool-Ergebnisse aus dem aktiven Prompt entfernt — nur die 5 aktuellsten bleiben. Die JSONL-Datei auf der Festplatte wird nie angetastet. Compaction findet nur im Speicher statt. Dexter arbeitet mit einem kleineren Fenster weiter, und die vollständige Historie ist immer noch da, wenn wir sie brauchen.
5. Die finale Antwort
Während der Schleife ist das LLM ein Entdecker: Es entscheidet, wonach als Nächstes gesucht wird. Wenn es aufhört, Tools anzufordern, ist es fertig und bereit zu antworten. In diesem Moment wechseln wir zu einem vollständig separaten LLM-Aufruf für die finale Antwort. Dieser zweite Aufruf erhält die ursprüngliche Anfrage plus jedes Tool-Ergebnis aus dem Scratchpad — einschließlich der Ergebnisse, die während der Context Compaction entfernt wurden.
Warum ein separater Aufruf?
Ich habe versucht, dasselbe LLM, das die Erkundung durchführt, auch die Antwort schreiben zu lassen. Das Problem war subtil: Das Modell verankerte sich an dem, was es zuletzt abgerufen hatte. Wenn der letzte Tool-Aufruf Insiderhandel zurückgab, begann die Antwort mit Insiderhandel und vergrub den Ergebnisvergleich — obwohl die Ergebnisse das Erste waren, wonach ich gefragt hatte.
Die Trennung der beiden Rollen löste das Problem. Der Entdecker sammelt. Der Antwortgenerator schreibt. Der Antwortgenerator sieht alles, was der Entdecker gefunden hat, und strukturiert die Antwort um meine ursprüngliche Frage herum — nicht um das, was zufällig als Letztes zurückkam.
Für unsere NVIDIA-Anfrage enthält die finale Antwort einen Ergebnisvergleich (gemeldet vs. Konsens), Insiderhandelsaktivitäten, zukunftsgerichtete Aussagen aus Abschnitt 7 und eine Synthese der Analystenreaktionen. Alles mit Quell-URLs.
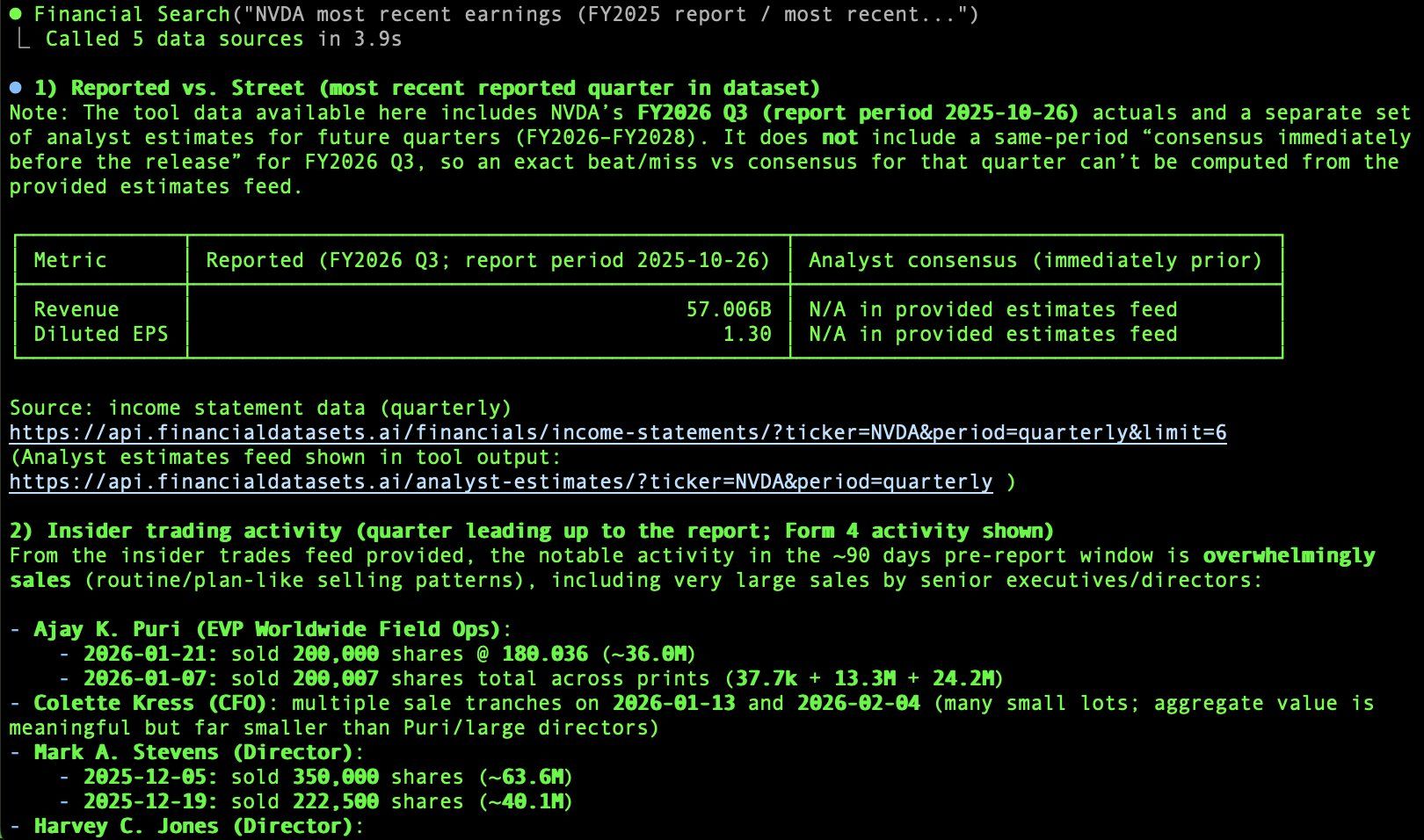
6. Evaluierung
Nichts von alledem zählt, wenn die Antworten falsch sind.
Das ist der Teil, den viele Leute überspringen, wenn sie einen Finanzagenten bauen. Fairerweise hätte ich ihn fast selbst übersprungen. Die ersten paar Wochen habe ich Dexter „evaluiert", indem ich ihm Fragen stellte und die Ausgabe las. Wenn es richtig aussah, machte ich weiter. Dann änderte ich eines Tages zwei Wörter in einer Tool-Beschreibung, und Dexter fing an, Quartals- und Jahresumsätze zu verwechseln. Ich bemerkte es drei Tage lang nicht. Und das war das letzte Mal, dass ich Evals auf Gefühl machte.
Dexter führt jetzt Evaluierungen offline durch, mit einem Datensatz aus Finanzfragen gepaart mit erwarteten Antworten. Jede Frage bekommt eine frische Agenteninstanz. Der Agent läuft, produziert eine Antwort, und ein separates LLM-als-Richter bewertet sie auf einer Skala von 0 bis 1. Ergebnisse werden in LangSmith protokolliert, um sie über die Zeit zu verfolgen.
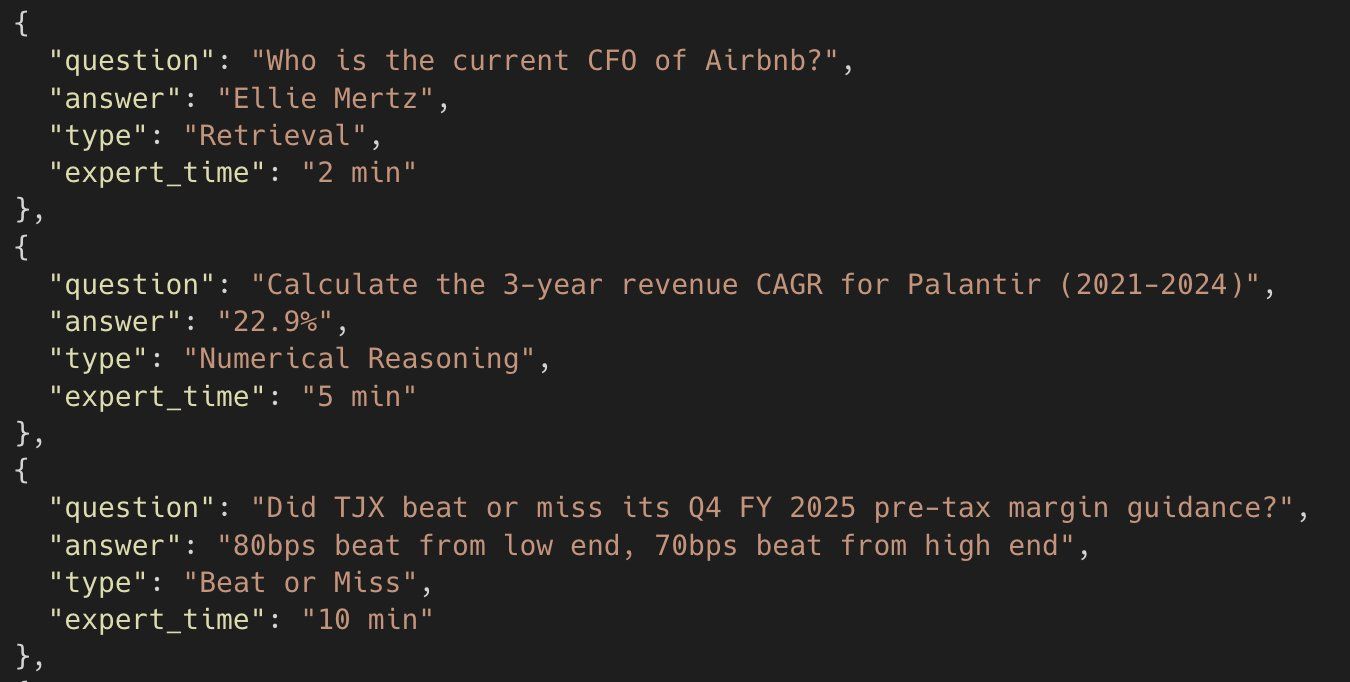
Die Bewertungsrubrik prüft spezifische Fakten: die richtigen Zahlen, das richtige Jahr, den richtigen Filing-Abschnitt. Aber sie prüft auch auf Widersprüche — Fälle, in denen die Antwort bekannten Daten widerspricht. Das fängt eine Fehlerklasse ab, die ich als wirklich problematisch empfinde: Dexter hat das richtige Tool aufgerufen, aber die Daten falsch gelesen, oder ein Subagent hat das falsche Sub-Tool gewählt und Dexters Haupt-LLM hat aus unvollständigen Ergebnissen halluziniert. Die Antwort liest sich richtig. Der Agent klingt selbstbewusst. Aber die Zahlen stimmen nicht. Ohne Evals rutschen diese durch.
Ich führe Evals vor jeder Änderung am System-Prompt, an Tool-Beschreibungen oder an der Routing-Logik durch. Man ändert den System-Prompt dutzende Male beim Bau eines Agenten. Das habe ich. Man braucht Evals. Sonst rät man nur, ob eine Änderung geholfen oder geschadet hat.
Abschließender Gedanke
Meine wichtigste Erkenntnis aus drei Jahren Agenten-Entwicklung: Halte die Dinge einfach. Der schwierigste Teil beim Bau von Dexter war die Entscheidung, was Dexter nicht tun sollte.
Was früher 30 Minuten Tab-Jonglieren, Fehlinterpretation von Filings und Kampf mit Pop-ups auf miserablen Finanznachrichtenseiten war, ist jetzt eine 30-Sekunden-Aufgabe. Fünf Tool-Aufrufe, ein Scratchpad und eine saubere finale Antwort mit Quellen. Ein einfaches, aber leistungsstarkes agentisches System.
Wenn du eine Sache aus diesem Artikel mitnimmst, hoffe ich, es ist diese: Bevorzuge einfache Architekturen und lass das Modell die Arbeit machen.
Der Dexter-Code ist hier: https://github.com/virattt/dexter
Einstieg in Large Language Models
Eine praktische Einführung in LLMs – was sie sind, wie sie funktionieren und wie man heute mit ihnen anfängt zu bauen.
Dexter: Ein autonomer Agent für tiefgehende Finanzanalyse
Dexter ist ein Open-Source-Agent für autonome Finanzanalyse, der denkt, plant und lernt – fähig, Quartalsberichte, SEC-Filings und Marktdaten in Sekunden auszuwerten.
Related Articles

